

Denetimsiz Öğrenme diğer adıyla Gözetimsiz Öğrenmenin ne olduğunu sizlere bu yazımda anlatmaya çalışacağım.
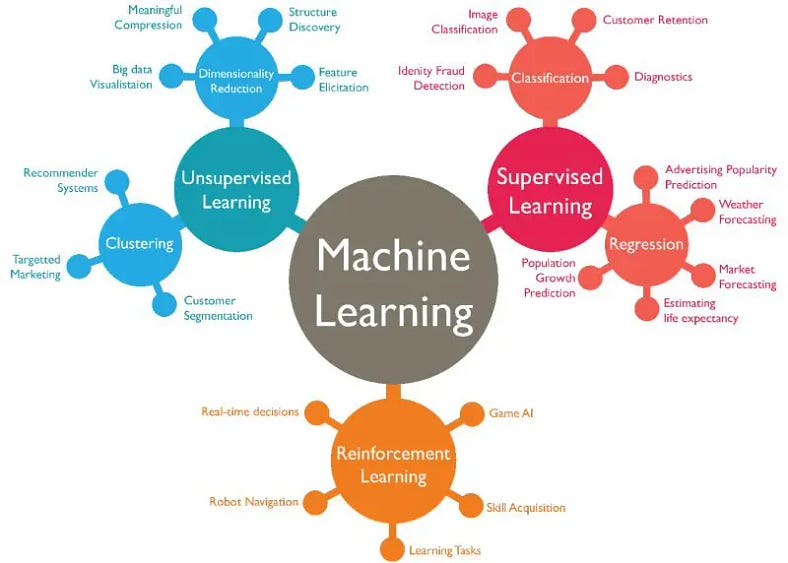
Öncelikle konuyu daha iyi kavrayabilmek için Denetimli Öğrenmenin ne olduğuna kısaca bir bakalım;
Bir modelin belirli bir girdiye dayanarak doğru çıktıyı tahmin etmesi için eğitildiği bir öğrenme yöntemidir. Etiketlenmiş veri kümesi kullanarak çalışır, yani her veri noktası için hem girdi (özellikler) hem de hedef çıktı değeri (etiket = label) sağlanır.

Denetimsiz Öğrenme (Unsupervised Learning)
Denetimsiz öğrenme yöntemlerinde, veri kümesi etiketlenmemiş veya hedef çıktı değeri sağlanmamış verilerden oluşur.
Algoritma veri kümesini analiz eder ve içerisindeki benzerlikler, gruplamalar veya yapılar gibi yapıları keşfetmeye çalışır. Bu süreçte, algoritma veri kümesindeki desenleri anlamaya çalışır ve veri noktalarını benzerliklerine veya özelliklerine göre gruplandırır.
Peki gruplamayı nasıl ve neleri kullanarak yapıyor?
- K-Ortalamalar (K-Means)
- Hiyerarşik Kümeleme Analizi (Hierarchical Cluster Analysis)
- Temel Bileşen Analizi (Principal Component Analysis)
K-Ortalamalar (K-Means)
Amaç, gözlemleri birbirilerine olan benzerliklerine göre kümelere ayırmaktır. Kümeler içi homojenliği çok yüksek yapmaktır.
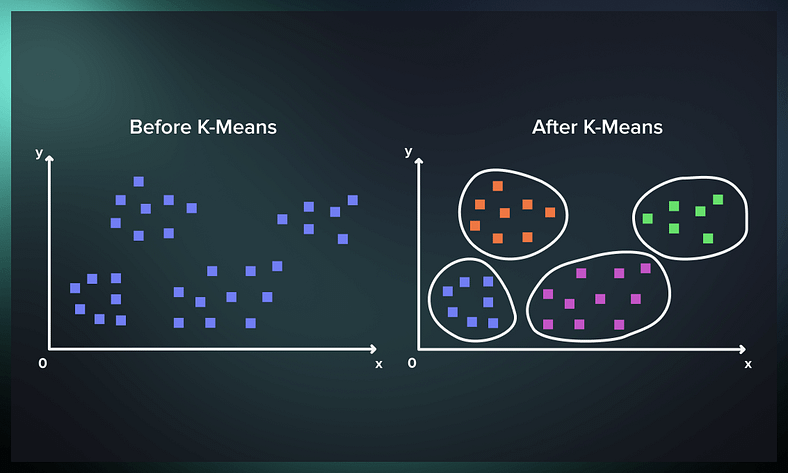
Birbirine olan benzerliklerine göre kümelendi.
Peki nasıl çalışır;
- Çalışmanın ilk adımı, küme sayısı belirlenir.
- Kaç tane küme sayısı belirlediysek o sayı kadar rastgele k merkez seçilir.
- Her bir gözlem için k merkezlere olan uzaklıklar hesaplanır.
- Her bir gözlem en yakın olduğu merkeze yani kümeye atanır ve kümeleme işlemi gerçekleşmiş olur.
- Başta rastgele yapılan k merkezler, atama işlemlerinden sonra artık merkez olmayabilir bu yüzden oluşan kümeler için tekrar merkez hesaplamaları yapılır.
- Bu işlem belirlenen bir iterasyon adedince tekrar edilir ve küme içi hata kareler toplamlarının toplamının (total within-cluster variation) minimum olduğu durumdaki gözlemlerin kümelenme yapısı nihai kümelenme olarak seçilir.
Bu oluşturduğum kümeler kendi içinde homojen birbirlerine göre heterojen olmalı, bunu nasıl yapabileceğimizi matematiksel olarak SSE, SSR ve SSD kullanılır.
Bu yöntem, algoritma, veri analizi, müşteri segmentasyonu, görüntü işleme ve doğal dil işleme gibi birçok alanda kullanılan etkili bir kümeleme yöntemidir.
Biz başta küme sayısını rastgele belirliyoruz, bu küme sayısını belirlemek için Elbow yöntemini kullanabiliriz.

Elbow Yöntemi Nedir?
Kümeleme (clustering) analizinde optimal küme sayısını belirlemek için kullanılan bir tekniktir. küme sayısının artmasıyla birlikte kümeleme algoritmasının ortaya çıkardığı hata miktarını (inertia veya toplam kare hatası, SSR,SSD,SSE) değerlendirir. Inertia, her bir veri noktasının kendi kümesinin merkezine olan uzaklıklarının karelerinin toplamıdır. Elbow yöntemi, inertia değerinin küme sayısıyla ilişkisini analiz ederek optimal küme sayısını belirlemeye çalışır.
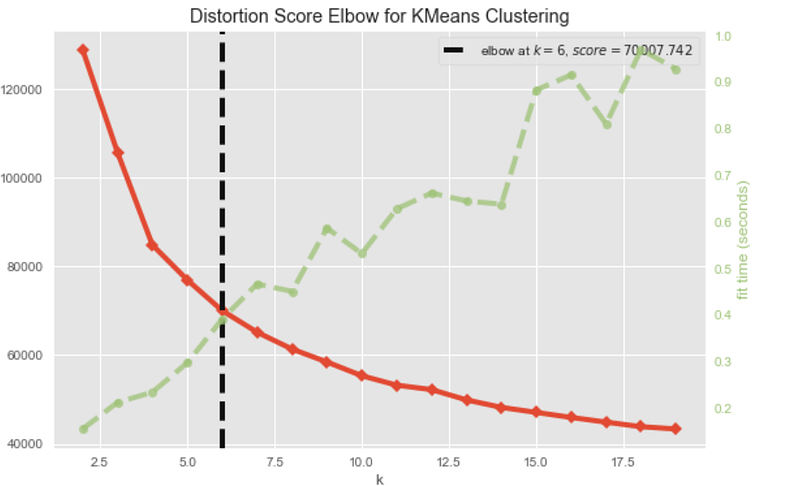
Burada gördüğümüz kesikli siyah çizgi değeri kaç kümeye ayaracağımız hakkında bizlere fikir verir.
kmeans = KMeans() elbow = KElbowVisualizer(kmeans, k=(2, 20)) elbow.fit(df) elbow.show() elbow.elbow_value_
Üzerinde çalıştığınız veri setinde “elbow.elbow_value_” elbow yöntemiyle küme sayısına ulaşabilirsiniz.
Hiyerarşik Kümeleme Analizi ( Hierarchical Cluster Analysis )
Veri noktalarını hiyerarşik bir yapıda kümelere ayırmak için kullanılan bir kümeleme yöntemidir. Veri noktaları bir ağaç yapısı olarak temsil edilir, her düğüm kümenin bir alt kümesini veya birleşimini temsil eder.
Hiyerarşik kümeleme analizi iki farklı yaklaşıma sahiptir:
- Aşağıdan Yukarıya (Agglomerative), Birleştirici Yaklaşım: Her veri noktası ayrı bir küme olarak başlar. Ardından, benzerlik veya uzaklık metrikleri kullanılarak en yakın iki küme birleştirilir. Bu birleştirme işlemi, benzerlik ölçütüne göre en yakın iki kümenin birleştirilmesiyle devam eder. Bu işlem, tüm veri noktaları tek bir küme haline gelene kadar tekrarlanır.
- Yukarıdan Aşağıya (Divisive), Bölümleyici Yaklaşım: Tüm veri noktaları tek bir küme olarak başlar. Bu küme içerisindeki benzer olmayan veri noktaları alt kümelere ayrılır. Bu ayrıştırma işlemi, veri noktaları alt kümelere ayrılmayacak kadar farklı olana kadar tekrarlanır.
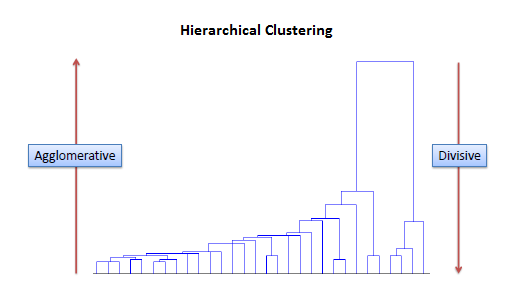
Linkage, benzerlik veya uzaklık ölçümlerine dayanarak, kümeleme işlemindeki farklı küme birleştirme veya ayrıştırma stratejilerini tanımlar.
Linkage bir sürü çeşidi olsa da en yaygın kullanılan “average linkage” ’dır.
Ortalama Bağlantı (Average Linkage); her iki kümeye ait tüm noktalar arasındaki uzaklıkların ortalaması, küme birleştirme veya ayrıştırma kararı için ölçüt olarak kullanılır. Ortalama bağlantı, bir denge sağlamaya çalışarak daha dengeli kümelemeler oluşturma eğilimindedir.
hc_average = linkage(df, "average")
Temel Bileşen Analizi ( Principal Component Analysis )
Çok değişkenli verinin ana özelliklerini daha az sayıda değişken/bileşen ile temsil etmektir. Başka bir ifade ile küçük miktarda bir bilgi kaybını göze alıp değişken boyutunu azaltmaktır.
Temel Bileşen Analizi bir boyut indirgeme yaklaşımıdır. Veri setinin boyutunu küçük miktarda bir bilgi kaybını göze alarak indirgeme işlemidir.
Temel Bileşen Analizi veri setini, bağımsız değişkenlerin doğrusal kombinasyonları ile ifade edilen bileşenlere indirger. Dolayısı ile bu bileşenler arasında korelasyon yoktur.
PCA; boyut azaltma, veri görselleştirme, gürültü azaltma ve veri sıkıştırma gibi birçok uygulama alanı bulunur.
Okuduğunuz için çok teşekkür ederim. Umuyorum ki faydalı bir paylaşım olmuştur.