

Yapay zeka (AI) ve makine öğrenimi (ML) alanlarında son yıllarda büyük gelişmeler kaydedildi. Bu ilerlemelerin önemli bir kısmı, doğal dil işleme (NLP) ve bilgisayarla görme (CV) gibi alanlarda devrim yaratan yeni mimarilerle sağlandı. Bu yazıda, bu yenilikçi teknolojilerin iki önemli temsilcisi olan Transformers ve Vision Transformers (ViT) üzerinde duracağız. Özellikle Vision Transformers'ın işleyişi, mimarisi ve uygulama alanları hakkında daha derinlemesine bilgi vereceğiz.
{kind=link}
Transformers
Transformers, 2017 yılında Google Brain araştırmacıları tarafından tanıtılan bir yapay sinir ağı mimarisidir. "Attention is All You Need" başlıklı makalede sunulan bu model, dil işleme görevlerinde çığır açıcı sonuçlar elde etmiştir.
Mimari ve Özellikler
Transformers mimarisinin temel bileşenlerini anlamak, bu teknolojinin gücünü ve geniş uygulama yelpazesini kavramak açısından önemlidir.
-
Self-Attention Mekanizması:
- Self-attention, dizideki her bir öğenin diğer tüm öğelerle olan ilişkisini hesaplar. Bu mekanizma, her öğenin konumuna ve içeriğine bağlı olarak ağırlıklar atar.
- Örneğin, "self-attention" terimi bir cümledeki her kelimenin diğer tüm kelimelerle olan ilişkisini nasıl değerlendirdiğini gösterir. Bu, modelin uzun menzilli bağımlılıkları ve karmaşık ilişkileri etkili bir şekilde yakalamasını sağlar.
- Matematiksel olarak, self-attention şu şekilde ifade edilir:
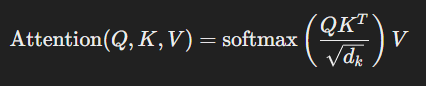 burada Q, K ve V sırasıyla sorgu (query), anahtar (key) ve değer (value) matrisleridir ve dkd_kdk anahtarların boyutudur.
burada Q, K ve V sırasıyla sorgu (query), anahtar (key) ve değer (value) matrisleridir ve dkd_kdk anahtarların boyutudur.
-
Paralel İşleme:
- RNN'lerin aksine, Transformers tüm diziyi aynı anda işler. Bu, hesaplama verimliliğini büyük ölçüde artırır ve eğitim süresini kısaltır.
- Paralel işleme, modelin GPU'lar gibi modern donanımlar üzerinde daha verimli çalışmasını sağlar.
-
Katmanlar ve Başlıklar:
- Transformers, çoklu self-attention başlıkları ve katmanlarından oluşur. Bu başlıklar, farklı alt-uzaylarda bilgiyi eşzamanlı olarak işler.
- Birden fazla başlığın kullanılması, modelin farklı dikkat pencereleri oluşturmasına ve daha zengin temsiller öğrenmesine olanak tanır.
- Çoklu başlık dikkat mekanizması (Multi-Head Attention):
 burada her bir başlık (head) kendi sorgu, anahtar ve değer matrislerini kullanarak dikkat hesaplamalarını gerçekleştirir.
burada her bir başlık (head) kendi sorgu, anahtar ve değer matrislerini kullanarak dikkat hesaplamalarını gerçekleştirir.
Uygulama Alanları
-
Doğal Dil İşleme (NLP):
- Makine çevirisi: Google Translate gibi uygulamalarda kullanılır.
- Dil modelleme: GPT, BERT gibi modellerin temelini oluşturur.
- Metin sınıflandırma ve duygu analizi gibi çeşitli NLP görevlerinde uygulanır.
- Konuşma tanıma, soru cevaplama ve metin oluşturma gibi ileri seviye NLP görevlerinde Transformers önemli rol oynar.
-
Genelleme Kapasitesi:
- Dil dışındaki sekans tabanlı verilerde (örneğin, biyolojik diziler) de başarıyla uygulanmaktadır.
- Zaman serisi analizi, genetik sekans analizi gibi alanlarda da Transformers mimarisinden faydalanılmaktadır.
Vision Transformers (ViT)
Vision Transformers (ViT), Transformers mimarisinin görsel veriler üzerinde uygulanmasıyla geliştirilmiş bir modeldir. 2020 yılında tanıtılan ViT, görüntü sınıflandırma ve diğer bilgisayarla görme görevlerinde üstün performans göstermiştir.
Mimari ve Özellikler
Vision Transformers mimarisi, geleneksel Convolutional Neural Networks (CNN) ile bazı benzerliklere sahiptir, ancak temelinde farklı bir yaklaşım barındırır.
-
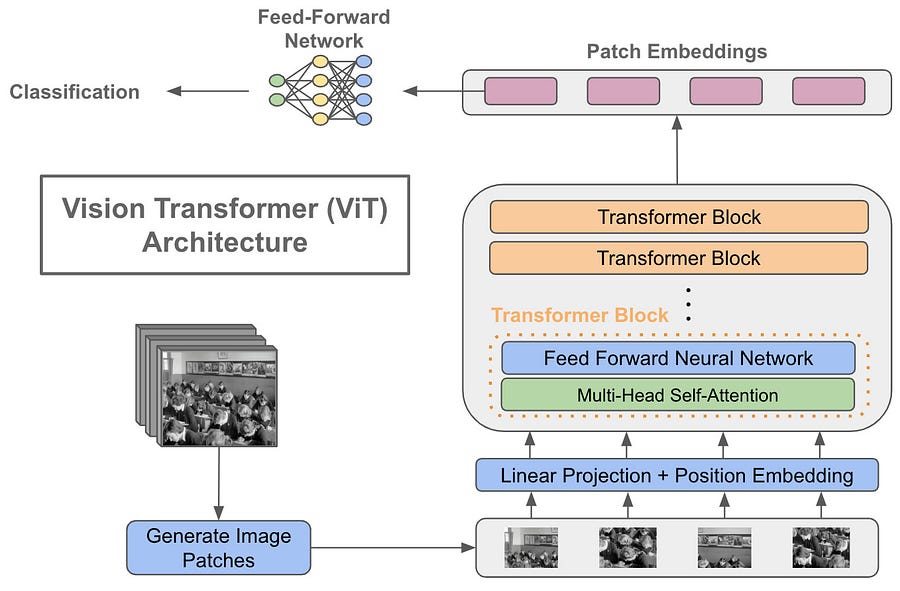
Patch Temsilciliği:
- Görüntüler, belirli boyutlardaki yamalara (patch) bölünür ve her yama, bir dizi öğe olarak temsil edilir. Bu yamalar, birer "kelime" gibi işlenir.
- Örneğin, 224x224 boyutunda bir görüntü 16x16 boyutundaki yamalara bölünürse, 196 adet yama elde edilir.
- Her yama, düzleştirilir ve daha sonra doğrusal bir projeksiyondan geçirilir.
-
Self-Attention Mekanizması:
- Tıpkı dil verisinde olduğu gibi, ViT de self-attention kullanarak yamalar arasındaki ilişkileri öğrenir.
- Bu mekanizma sayesinde model, görüntüdeki farklı bölgeler arasındaki uzun menzilli bağımlılıkları yakalayabilir.
- Yamalar arasındaki dikkat, modelin farklı görsel özellikleri daha iyi öğrenmesine olanak tanır.
-
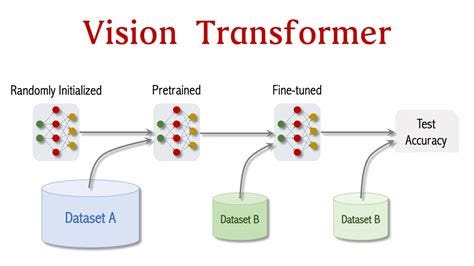
Önceden Eğitilmiş Modeller:
- ViT, büyük veri kümeleri üzerinde önceden eğitilerek, çeşitli bilgisayarla görme görevlerinde kullanılabilecek güçlü bir model haline getirilir.
- Örneğin, ImageNet veri setinde önceden eğitilen bir ViT, birçok görsel görevde başarılı sonuçlar verebilir.
- Transfer öğrenme ile farklı veri kümeleri üzerinde ince ayar yapılarak (fine-tuning) yüksek performans elde edilebilir.

Avantajlar ve Zorluklar
-
Avantajlar:
- Daha İyi Performans: ViT, özellikle büyük veri kümeleri üzerinde eğitildiğinde, geleneksel CNN'lere göre üstün performans gösterebilir.
- Esnek ve Genelleyici: Self-attention mekanizması sayesinde, ViT daha esnek ve genelleyici bir yapı sunar.
- Uzun Menzilli Bağımlılıklar: ViT, self-attention mekanizması sayesinde görüntünün uzak bölgeleri arasındaki ilişkileri daha iyi öğrenir.
-
Zorluklar:
- Büyük Veri İhtiyacı: ViT'nin etkili olabilmesi için çok büyük veri kümeleri üzerinde eğitilmesi gerekmektedir. Bu, küçük veri kümeleriyle çalışan projeler için bir dezavantaj olabilir.
- Hesaplama Maliyeti: ViT, özellikle büyük modellerde, yüksek hesaplama maliyetlerine sahip olabilir.
- İnce Ayar (Fine-Tuning) Gereksinimi: ViT modellerinin farklı veri kümelerinde etkili olabilmesi için genellikle ince ayar yapılması gerekmektedir.
Uygulama Alanları
-
Görüntü Sınıflandırma:
- ViT, ImageNet gibi büyük veri kümelerinde yüksek doğruluk oranları elde etmiştir. Bu, birçok endüstriyel ve araştırma alanında kullanılabilir.
- Farklı veri kümeleri üzerinde de yüksek performans göstererek, esnek ve genelleyici bir sınıflandırma modeli sunar.
-
Nesne Tespiti ve Segmentasyon:
- ViT tabanlı modeller, nesne tespiti ve görüntü segmentasyonu gibi görevlerde de başarılıdır. Bu, otonom araçlar ve medikal görüntüleme gibi alanlarda büyük potansiyele sahiptir.
- Nesne tespiti ve segmentasyon görevlerinde, farklı nesnelerin ve bölgelerin doğru şekilde tanımlanması sağlanır.
-
Medikal Görüntüleme:
- ViT, radyoloji ve diğer medikal alanlarda görüntü analizi için kullanılmaktadır. Bu, hastalık teşhisi ve tedavi planlamasında önemli bir rol oynayabilir.
- Medikal görüntülerin analizinde, özellikle karmaşık ve küçük ayrıntıların tespitinde ViT modelleri oldukça etkilidir.
Vision Transformers Uygulama Örneği
Aşağıda, Vision Transformers'ı kullanarak basit bir görüntü sınıflandırma görevi gerçekleştiren bir Python kodu verilmiştir. Bu örnekte, ViT modelini kullanarak MNIST veri setindeki el yazısı rakamları sınıflandıracağız.
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from transformers import ViTForImageClassification, ViTFeatureExtractor
# Veriyi yükleyip işleme
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# Model ve özütleyici tanımlama
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224', num_labels=10)
# Eğitim süreci
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
for epoch in range(3): # Kısa bir eğitim süreci için epoch sayısını az tuttuk
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images).logits
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{3}, Loss: {loss.item()}')
# Test süreci
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images).logits
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Test Accuracy: {100 * correct / total:.2f}%')
Karşılaştırma ve Gelecek Perspektifleri
Transformers ve Vision Transformers, farklı veri türlerine yönelik olsalar da, benzer prensipler üzerine kuruludur. Transformers dil verilerinde, ViT ise görsel verilerde devrim yaratmıştır. Bu iki modelin ortak noktaları ve başarıları, gelecekte bu yaklaşımların birleşik modellerde kullanılabileceğini düşündürmektedir.
Gelecekte, bu teknolojilerin daha geniş ve çeşitli veri kümeleri üzerinde eğitilmesi, daha da güçlü ve genelleyici modellerin ortaya çıkmasını sağlayacaktır. Ayrıca, Transformers ve ViT'nin birlikte kullanımı, çok modaliteli (multi-modal) yapay zeka uygulamalarının önünü açabilir. Örneğin, bir modelin hem metin hem de görüntü verilerini işleyebilmesi, daha karmaşık ve sofistike görevlerin üstesinden gelmesini sağlayacaktır.
Birleşik modellerin geliştirilmesi, daha güçlü ve genelleyici yapay zeka çözümlerinin ortaya çıkmasına olanak tanıyacaktır. Bu, özellikle otonom sistemler, tıp, finans ve daha birçok alanda yenilikçi uygulamaların geliştirilmesine kapı aralayacaktır.
Sonuç
Transformers ve Vision Transformers, yapay zeka ve makine öğrenimi alanlarında büyük ilerlemeler sağlayan iki önemli teknolojidir. Self-attention mekanizması ve paralel işleme yetenekleri sayesinde, bu modeller dil işleme ve görsel görevlerde üstün performans sergilemiştir. Gelecekte, bu teknolojilerin daha da geliştirilmesi ve yeni uygulama alanlarına yayılması beklenmektedir. Bu, AI alanında daha sofistike ve güçlü çözümlerin geliştirilmesine olanak tanıyacaktır.
Transformers ve ViT'nin sürekli gelişimi, yapay zeka araştırma ve uygulama alanlarında yeni ufuklar açmaya devam edecektir. Bu teknolojilerin entegrasyonu ve gelişimi, daha etkili ve verimli yapay zeka sistemlerinin yaratılmasını sağlayarak, toplumsal ve ekonomik alanlarda önemli katkılar sunacaktır.
Kaynakça
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is All You Need. arXiv preprint arXiv:1706.03762.
- Makale: Attention is All You Need
-
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929.
- Makale: An Image is Worth 16x16 Words
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI.
-
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. European Conference on Computer Vision (ECCV).
-
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A Simple Framework for Contrastive Learning of Visual Representations. International Conference on Machine Learning (ICML).
-
GitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
- Repository: Hugging Face Transformers
-
Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollar, P. (2017). Focal Loss for Dense Object Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
- Chatgpt :)
Bu kaynaklar, Transformers ve Vision Transformers üzerine yapılan araştırmalar ve uygulamalar hakkında daha fazla bilgi edinmek isteyenler için faydalı olacaktır.